
Voice AI Call Agent
Real-time AI phone agent with sub-second latency
Role
Architect & Engineer
Year
2026
Status
Private
Overview
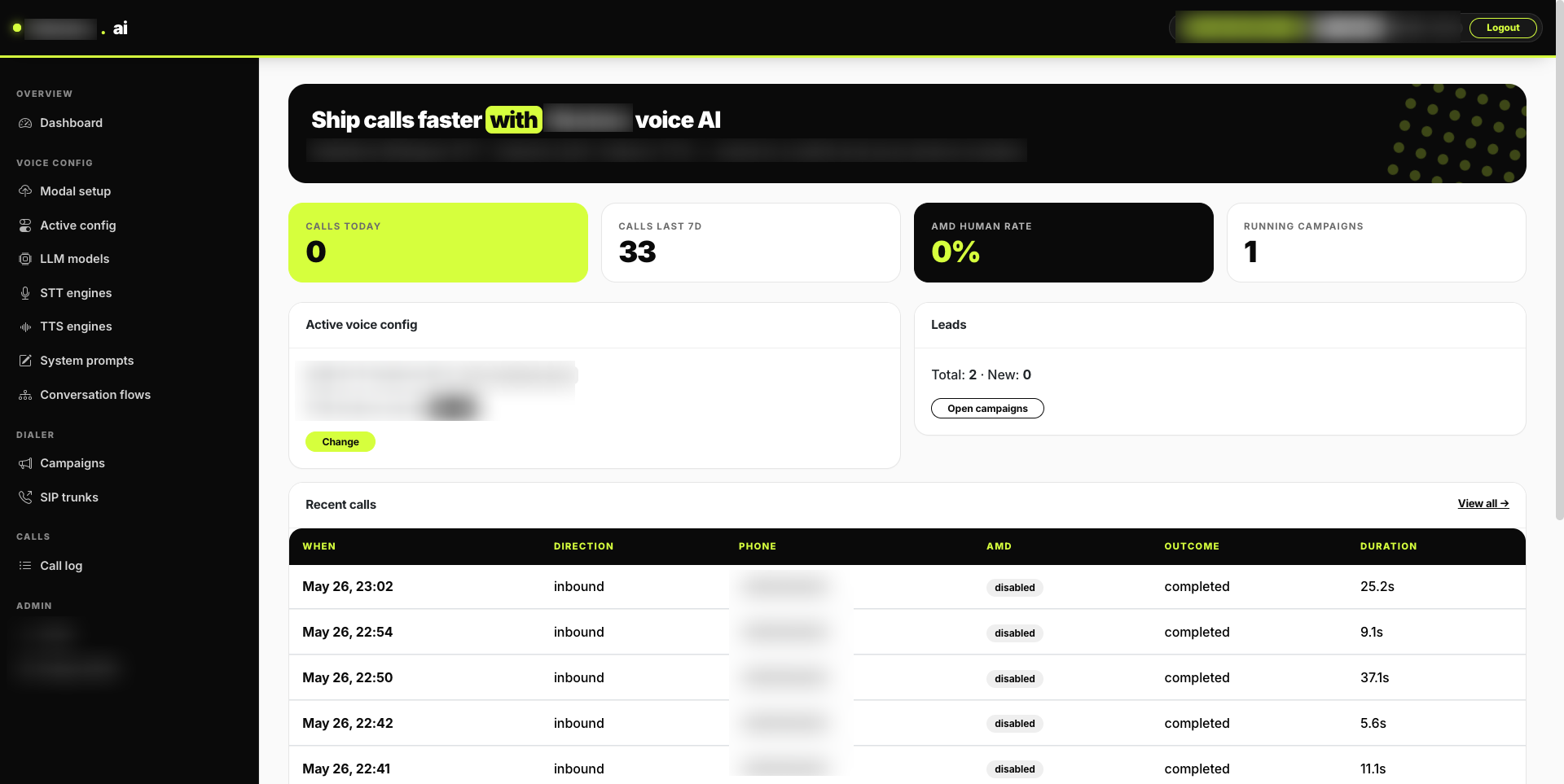
A full voice-AI stack built for production telephony. Combines a low-latency speech pipeline, a visual conversation flow editor, a campaign-based outbound dialer, automated post-call data extraction, and synced call recording. Engines (STT, LLM, TTS) are configured at runtime so they can be hot-swapped per call without restarts. Designed to run agent logic on the telephony edge while offloading GPU inference to serverless infrastructure for cost-efficient scaling.
Highlights
Average time-to-talk: 833–1311 ms across production calls
Supports both chat-style (STT+LLM+TTS) and Realtime (speech-to-speech) modes
Edge agent + serverless GPU split removes per-frame network hops
Per-campaign concurrency limits and retry policies
Graceful fallback chain for missing plugins or provider outages
Capabilities
Low-Latency Voice Pipeline
STT → LLM → TTS pipeline tuned for ~800–1300ms time-to-talk. Silero VAD endpointing, preemptive generation, and PCM streaming minimize time-to-first-audio.
Multi-Provider LLM Layer
Pluggable LLM back-ends — Gemini, OpenAI (chat + Realtime speech-to-speech), DeepSeek, Cloudflare Workers AI, and self-hosted vLLM — selected per call from an admin UI.
Realtime Speech-to-Speech
Optional one-component pipeline using the OpenAI Realtime API for ~300–500ms voice-to-voice latency, with transcripts captured via parallel ASR for post-call analysis.
Visual Conversation Flows
Drag-and-drop state-machine editor for call flows. Each node carries its own prompt, transitions, and tool calls. Flows are scoped per LLM and versioned independently.
Campaign-Based Outbound Dialer
Long-lived dialer service places calls via the telephony SDK, tracks lead state (queued → calling → completed / no-answer / voicemail), retries with attempt caps, and handles concurrency limits per campaign.
CSV Lead Ingestion
Two-step CSV upload with auto-detected field mapping. Unmapped columns become per-lead template variables surfaced as {{tokens}} in prompts.
Post-Call Data Extraction
After hangup, the transcript is sent to the active LLM with a JSON schema derived from the campaign’s expected fields. Type-coerced output is stored as a structured opportunity record.
Recording with Synced Captions
Audio-only recordings are streamed to object storage. The call detail UI plays the recording with a custom audio player and highlights each transcript turn in lock-step with playback.
Hot-Swappable Engine Config
STT / LLM / TTS / Flow are fetched per call from a config API. Activate a different engine from the admin UI and the next call uses it — no worker restart required.
Tech stack
Privacy
This is a private project. Architecture, capabilities, and outcomes shown here are generalized; client identity, domain specifics, infrastructure addresses, and operational data are intentionally omitted.